Clustering is one of the most common unsupervised Machine Learning tasks. Solr is shipped with a clustering module based on Carrot2 built-in algorithms. Carrot2 comes with 4 algorithms: Lingo, STC, kMeans and Lingo3D each one mapped to a clustering engine. The first three are open-source whereas the last one is commercial. When this approach is used, clustering takes place in memory. Other frameworks, such as Mahout, can be used to do the clustering “off-line.”
In this post a dataset of Medium articles index into a collection names medium_articles will be used. The dataset consists of several fields however, only two of which are considered: title and text which are required for logical mapping of fields to the clustering algorithm.
Enabling Clustering
Since the clustering module is not enabled by default, it should be enabled in solrconfig.xml through two elements: searchComponenet and a requestHandler. There are commented stubs inside solrconfig.xml which can be used and tweaked. Below is the libraries that need to be loaded for the clustering to work:
<lib dir="${solr.install.dir:../../../..}/contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-clustering-\d.*\.jar" />searchComponent element defines the available engines and which one is the default. requestHandler defines the HTTP handler responsible for accepting requests, calling the clustering algorithm with the specified parameters and sending back the response. The following snippets are examples of these two components:
<searchComponent name="clustering" class="solr.clustering.ClusteringComponent">
<!-- Lingo clustering algorithm -->
<lst name="engine">
<str name="name">lingo</str>
<str name="carrot.algorithm">org.carrot2.clustering.lingo.LingoClusteringAlgorithm</str>
</lst>
<!-- An example definition for the STC clustering algorithm. -->
<lst name="engine">
<str name="name">stc</str>
<str name="carrot.algorithm">org.carrot2.clustering.stc.STCClusteringAlgorithm</str>
</lst>
<lst name="engine">
<str name="name">kmeans</str>
<str name="carrot.algorithm">org.carrot2.clustering.kmeans.BisectingKMeansClusteringAlgorithm</str>
<str name="carrot.resourcesDir">clustering/carrot2</str>
</lst>
</searchComponent><requestHandler name="/clustering"
class="solr.SearchHandler">
<lst name="defaults">
<bool name="clustering">true</bool>
<bool name="clustering.results">true</bool>
<bool name="carrot.produceSummary">true</bool>
</lst>
<!-- Append clustering at the end of the list of search components. -->
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>The requestHandler is accepts several engine hyper-parameters and some of the properties of the returned clusters. Probably the most important ones are these ones:
| Parameter | Description |
clustering.engine | Which controls the engine to be used for clustering. Open source engines are Lingo, STC, and k-Means which map to these values: lingo, stc, and kmeans respectively |
| carrot.produceSummary | When true the clustering component will run a highlighter pass on the content of logical fields pointed to by carrot.title and carrot.snippet. Otherwise full content of those fields will be clustered |
| carrot.snippet | The field (alternatively comma- or space-separated list of fields) that should be mapped to the logical document’s main content |
| carrot.title | The field (alternatively comma- or space-separated list of fields) that should be mapped to the logical document’s title |
After enabling the clustering feature, the following request should return the search result along with its clusters:
http://server_host:8983/solr/medium_articles/clustering?q=*:*&fl=title_s,id&rows=2000&carrot.snippet=text_t&carrot.title=title_sNote: if the result has only one cluster titled “Other Topics”, make sure carrot.title and carrot.snippet are passed correctly.
Note: enabling carrot.produceSummary and using lingo algorithm increases the cohesion and label quality of the clustering.
Visualizing Clusters
To visualize the result clusters, a Banana result clustering panel can be used. Assuming Banana and Solr are up, running and properly connected, on Docker or any other means, cluster visualization is a piece of cake! 🍰
Pull the latest Banana Standalone version, configure it properly to read from the articles collection and add a resultCluster panel with the following settings as an example:
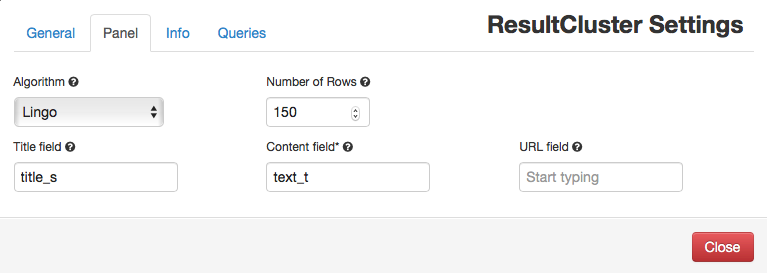
Close the settings window and wait for a few moments and an interactive labeled result clusters should be rendered!
Clicking a cluster adds a filter query to the dashboard with the value of the label that has been clicked which is different from viewing the cluster documents which will be supported in upcoming versions.
Note: the more rows are fetched, the more clusters tend to be computed.